어텐션 메커니즘은 입력의 각 부분이 출력의 각 부분에 얼마나 주의를 기울여야 하는지를 학습하는 방법이다.
1. seq2seq(sequence to sequence)
초기의 모델은 seq2seq(sequence to sequence)의 형태를 많이 따르고 있었다.
14-01 시퀀스-투-시퀀스(Sequence-to-Sequence, seq2seq)
이번 실습은 케라스 함수형 API에 대한 이해가 필요합니다. 함수형 API(functional API, https://wikidocs.net/38861 )에 대해서 우선 숙지 후…
wikidocs.net

하지만, seq2seq의 형태를 따르게 되면 인코더 부분에서 들어온 모든 input이 하나의 context 벡터에 저장되기 때문에 sequence의 길이가 길어짐에 따라 information loss가 불가피하게 발생한다.
또한, sequence의 길이가 길어짐에 따라 Gradient가 소실되거나 폭발하는 경우가 발생한다.
그리하여, information loss의 해결책으로 고안해낸 메커니즘이 Attention Mechanism이다.
2. 어텐션 메커니즘 (Attention Mechanism)
15-01 어텐션 메커니즘 (Attention Mechanism)
앞서 배운 seq2seq 모델은 **인코더**에서 입력 시퀀스를 컨텍스트 벡터라는 하나의 고정된 크기의 벡터 표현으로 압축하고, **디코더**는 이 컨텍스트 벡터를 통해서 출력 …
wikidocs.net
어텐션 메커니즘의 기본적인 아이디어는 Decoding을 수행하는 매 순간, Incoder의 모든 입력값들을 참조한다는 것이다.
이때, 모든 입력값들을 참조하되, 연관이 있는 입력값에 더욱 집중(Attention)하여 보게된다.

Attention 함수는 기본적으로 Query, Key-Value를 입력으로 받아 Attention Value를 출력한다.
이때 Query는 t 시점의 디코더 셀에서의 은닉 상태를
Key-Value는 모든 시점의 인코더 셀의 은닉 상태들을 말한다.
Dot-Product Attention을 예로 들어보자.

1. Query와 Value의 Dot(내적)을 통해 Attention Score을 구한다.

2. Attention Score을 softmax를 이용하여 Attention Distribution을 구한다.
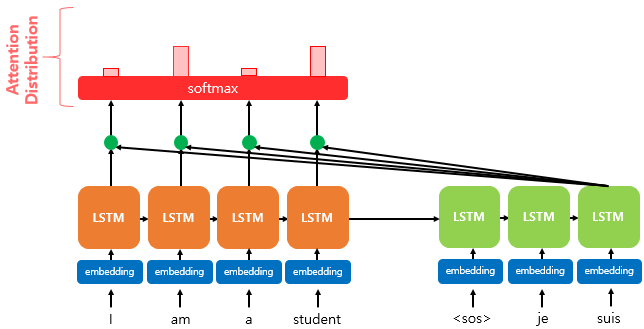
3. 각 인코더의 어텐션 가중치와 은닉 상태를 가중합(Weighted sum) 하여 Attention Value을 구한다.

4. 어텐션 값과 디코더의 t 시점의 은닉 상태를 연결한다.(Concatenate)

5. 연결된 디코더의 은닉 상태를 가지고 나머지 seq2seq model을 진행한다.

Attention 모델을 사용할 경우 디코더의 은닉층과 유사한 인코더의 은닉층에 더욱 영향을 받아 학습을 할 수 있기 때문에 학
습에 더욱 유리하다.
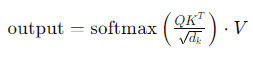
또한 각각의 단어들의 상관관계를 그린 Attention Map도 그릴 수 있다.


'AI Tech' 카테고리의 다른 글
| Matplotlib 기초 (0) | 2024.08.20 |
|---|---|
| "Auto-regressive" and "Teacher Focing" and "Scheduled Sampling" (0) | 2024.08.16 |
| 가중치 초기화 (Weight Initialization) (0) | 2024.08.13 |
| 활성 함수 (Activation Functions) (0) | 2024.08.13 |
| 손실 함수 (Loss Function) (0) | 2024.08.13 |



